Hello everyone,
I'm currently facing a challenge that I'm not getting anywhere with.
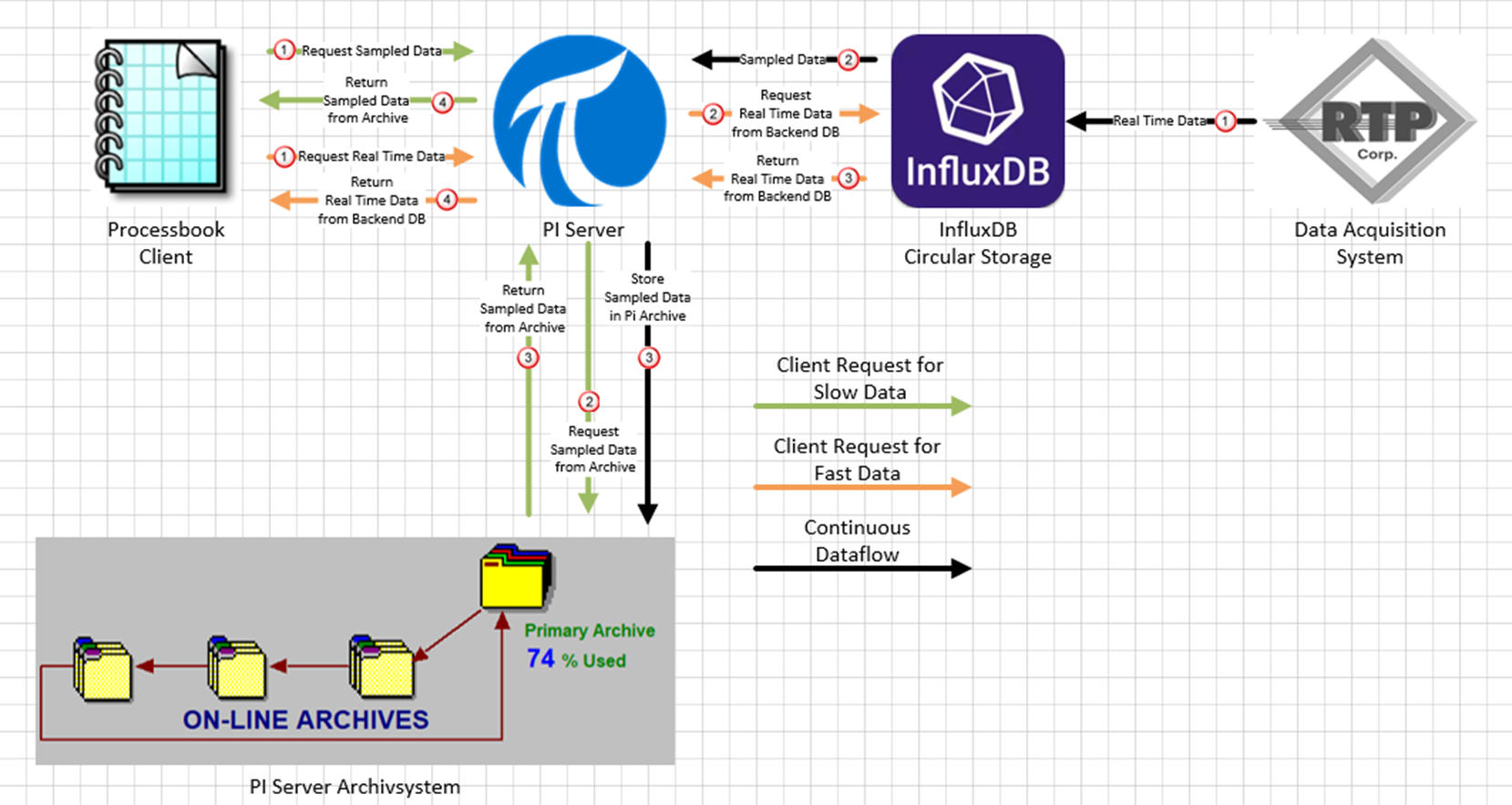
We would like to use the PI Data Archive for long-term storage of low-resolution process data. At the same time, high-resolution data from a ring buffer (InfluxDB) should also be made available to users via the PI Server.
In concrete terms, this means that high-resolution data is stored in the backend system (InfluxDB) for 30 days. Low-resolution data is stored in the PI Data Archive. Both types of data should be accessible via PI products such as ProcessBook, PI Vision, etc.
Our current PI system is very old and maps this architecture using a COM connector. We currently use an “ECHO-DB”, which we would now like to replace with InfluxDB.
The desired infrastructure essentially looks as shown in the attached picture. The old infrastructure is almost identical, but uses the ECHO DB and the COM connector.
It is important to mention that we do not want to integrate the high-resolution data directly into the PI system, as this would take up too much storage space in long-term archiving. In addition, there is no ring buffer functionality in the PI system without adapting the license model.
Now to my question:
What possibilities are there to forward data requests to the PI server to a backend system, similar to what our old COM connector did? Is it possible to develop software using the PI SDK that integrates new PI classes and functions for data retrieval?
I look forward to your ideas and suggestions!