

I am trying to configure my PI tag to be able to read data from an sql database.
the query works well and I just want to fecth the latest Cd_mean value. how can I configure my PI tag to store that value in a PI tag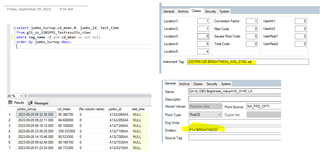
I am trying to configure my PI tag to be able to read data from an sql database.
the query works well and I just want to fecth the latest Cd_mean value. how can I configure my PI tag to store that value in a PI tag

